
About Me
I am a final-year Ph.D. candidate in Show Lab at National University of Singapore, supervised by Prof. Mike Shou. I received my bachelor’s degree and master’s degree from the Image Processing Center of Beihang University, supervised by Prof. Zhenwei Shi, also working closely with Prof. Zhengxia Zou.
Building omni world models: generative models that can understand, simulate, and interact with the visual world across modalities.
- Intervention: intervening in the virtual world in human desired ways (MotionDirector, P-Flow).
- Autonomy: advancing generative models to evolve and self-evlove (EvolveDirector, DoraCycle).
- Omni-modality: unifying vision and language within a unified modeling framework (DoraCycle, FlowInOne).
- Efficiency & Downstream tasks: making diffusion models faster (Glance), and utilizing the world knowlege in downtream tasks (Dream.exe).
I am open to new ideas, discussions, and possible collaborations. Feel free to reach out.
News
- 2025.09: Invited talk at Jump Trading, Singapore.
- 2025.07: Invited talk at WAIC 2025, Shanghai, “Advancing Visual Generation”.
- 2025.02: DoraCycle got accepted by CVPR 2025.
- 2024.09: EvolveDirector got accepted by NeurIPS 2024.
- 2024.07: Two papers, MotionDirector (Oral) and DragAnything, got accepted by ECCV 2024.
- 2024.02: Three papers, VideoSwap, X-Adapter, and DynVideo-E, got accepted by CVPR 2024.
- 2023.10: Foundational T2V generation model Show-1
released!
- 2023.10: Two papers, Mix-of-Show and DatasetDM, accepted by NeurIPS 2023.
- 2023.07: Invited talk at OPPO Research Institute, “Text-Driven Avatar Auto-Creation”.
- 2023.04: A collection of papers on video diffusion models: Awesome-Video-Diffusion
.
- 2023.03: Our paper for avatar auto-creation was accepted by CVPR 2023.
- 2022.08: One first-authored paper selected as ESI Highly Cited Paper.
- 2022.07: Castle in the Sky
accepted by IEEE Transactions on Image Processing.
- 2022.01: Awarded the Distinguished Graduates of Beijing.
- 2021.09: Awarded the National Scholarship.
Selected Publications
Check out full publication list at my Google Scholar profile.
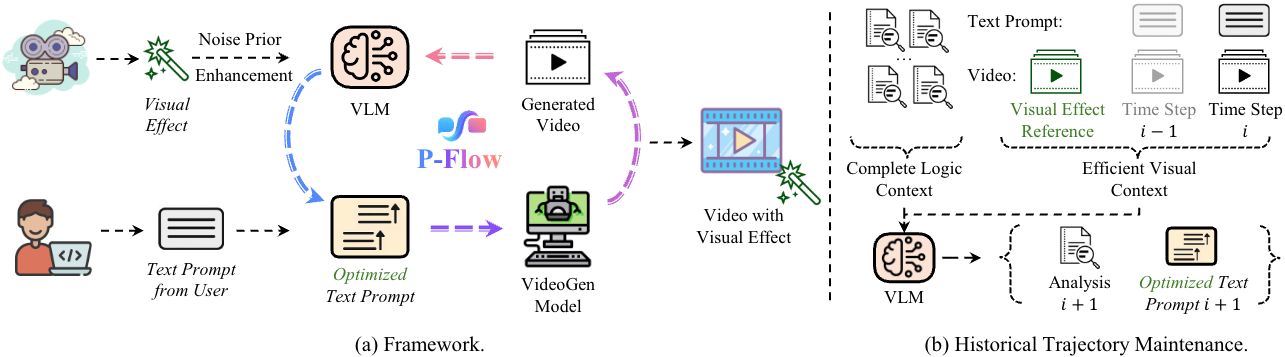
Dream.exe: Can Video Generation Models Dream Executable Robot Manipulation?
The International Conference on Machine Learning, FoGen Workshop, 2026
Rui Zhao*, Kaiming Yang*, Jifeng Zhu, Siyang Chen, Ziqi Wang, Weijia Wu, Kevin Qinghong Lin, Heng Wang, Mike Zheng Shou.
[arXiv]
[Github]
Spotlight. *equal contribution.
EvolveDirector: Approaching Advanced Text-to-Image Generation with Large Vision-Language Models
The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
Rui Zhao, Hangjie Yuan, Yujie Wei, Shiwei Zhang, Yuchao Gu, Lingmin Ran, Xiang Wang, Jay Wu, David Zhang, Yingya Zhang, Mike Zheng Shou.
[arXiv][Hugging Face]
[Github]
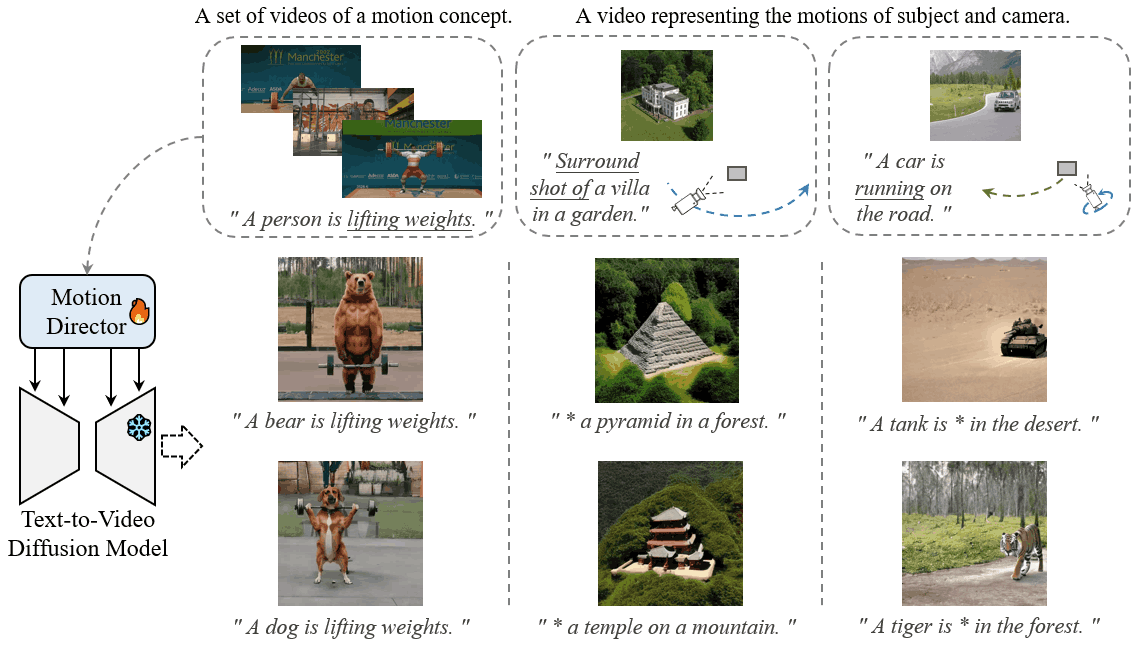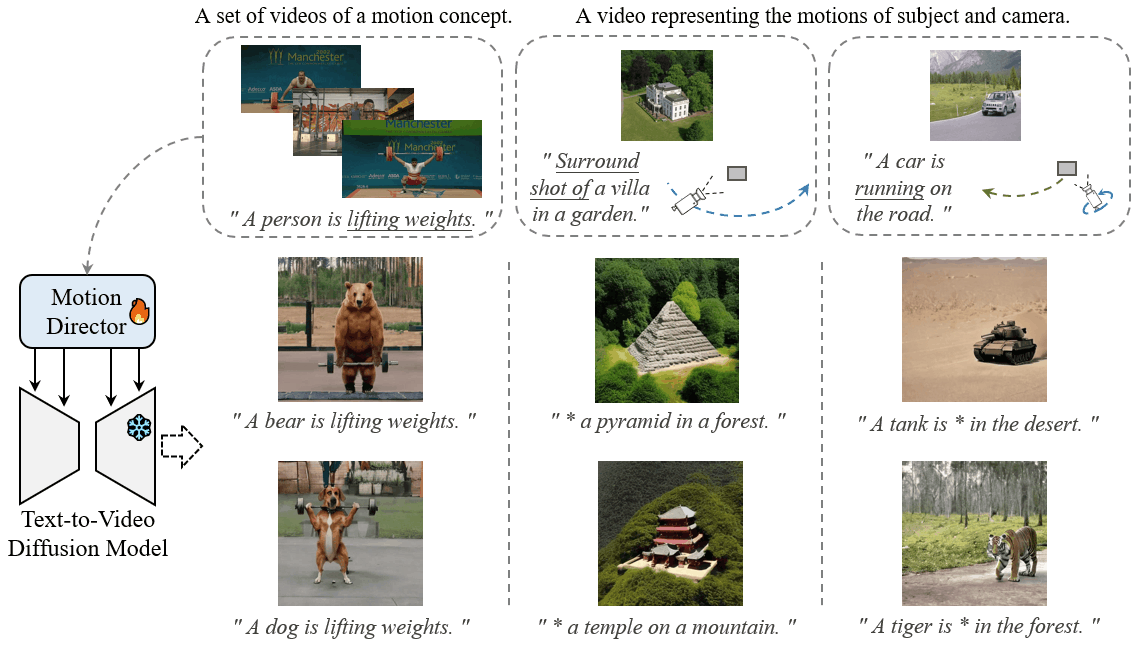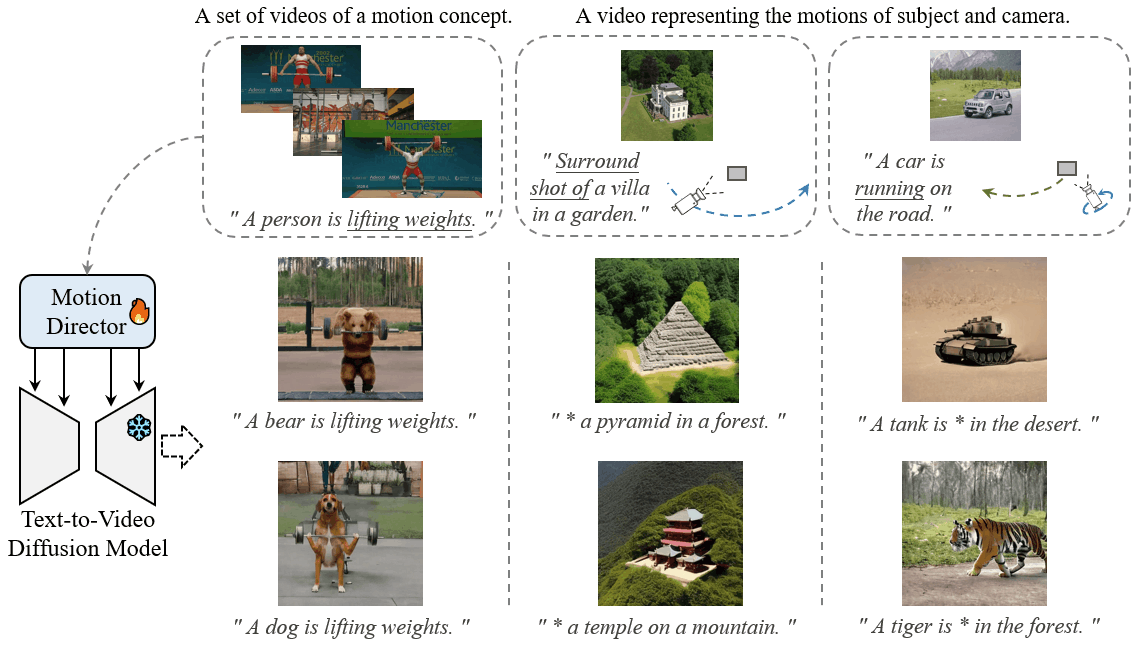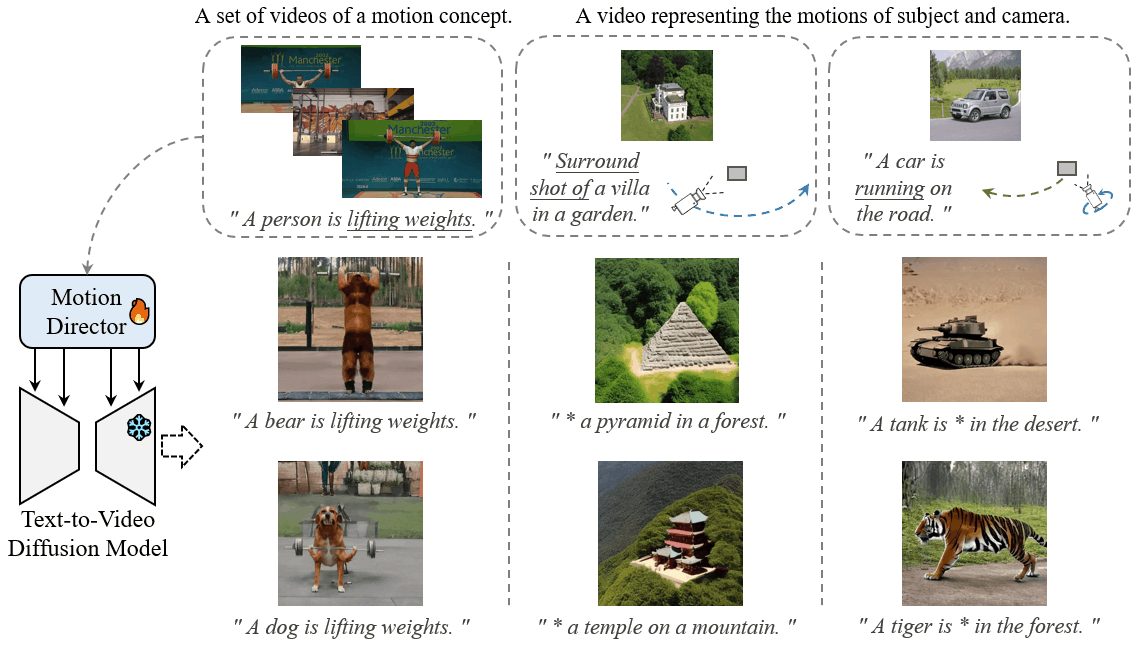
MotionDirector: Motion Customization of Text-to-Video Diffusion Models
Proceedings of the European Conference on Computer Vision, 2024
Rui Zhao, Yuchao Gu, Jay Zhangjie Wu, David Junhao Zhang, Jiawei Liu, Weijia Wu, Jussi Keppo, Mike Zheng Shou
[Project Page][arXiv]
[Github 
🎙️ Oral Presentation, Acceptance Rate: 2.3%.
🤗 Featured in Hugging Face “Spaces of the Week 🔥” trending list.
📃 Featured in “Top 40 most cited papers of ECCV 2024” list by AIR-SUN.

Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation
International Journal of Computer Vision, 2024
David Junhao Zhang†, Jay Zhangjie Wu†, Jia-Wei Liu†, Rui Zhao, Lingmin Ran, Yuchao Gu, Difei Gao, Mike Zheng Shou (†equal contribution)
[Project Page][arXiv]
[Github

Zero-Shot Text-to-Parameter Translation for Game Character Auto-Creation
The IEEE Conference on Computer Vision and Pattern Recognition, 2023
Rui Zhao, Wei Li, Zhipeng Hu, Lincheng Li, Zhengxia Zou, Zhenwei Shi, and Changjie Fan
[PDF]
Media coverage: [NewScientist] Character creator AI puts Barack Obama – or anyone – in a video game || [游戏日报] 网易伏羲“文字捏脸”方向论文入选CVPR会议,称已应用于《逆水寒手游》 || CVPR 2023 | 网易伏羲5篇论文入选 包含文字捏脸等业内首创工作 || [AUTOMATON] Researchers report technological breakthroughs in using AI to “make characters by asking with words”. (in Japanese, for English version, please refer to reprint 1 and reprint 2) || [Nazology] "Character creation support AI" that creates the ideal face specified in the sentence is now available! .

Castle in the Sky: Dynamic Sky Replacement and Harmonization in Videos
IEEE Transactions on Image Processing, 2022
Zhengxia Zou, Rui Zhao, Tianyang Shi, Shuang Qiu, and Zhenwei Shi
[PDF][Project Page]
[Github
Featured apps: Weights & Biases, a ML developer tool with 100,000+ practitioners.
Media coverage:
[TNW] This open-source AI tool can make your video spectacular with sky replacement effects ||
[Better Programming] The Top 10 Trending ML Projects of 2020.

High-resolution remote sensing image captioning based on structured attention
IEEE Transactions on Geoscience and Remote Sensing, 2021
Rui Zhao, Zhenwei Shi, and Zhengxia Zou
[PDF]
🏆️ ESI Highly Cited Paper*
* received enough citations to place in the top 1% of the academic field of Geosciences based on publication year. [Clarivate]
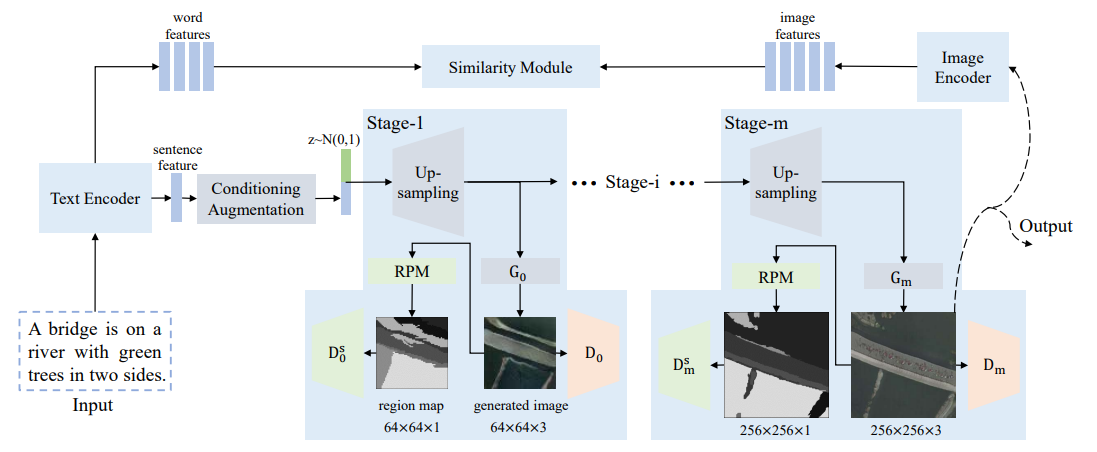
Text to Remote Sensing Image Generation With Structured Generative Adversarial Networks
IEEE Geoscience and Remote Sensing Letters, 2022
Rui Zhao, Zhenwei Shi
[PDF]
Selected Honors
- 2024 Show Lab Annual Award ($3000)
- 2022 The Distinguished Graduates of Beijing (Top 1%)
- 2021 National Scholarship, Ministry of Education of China (Top 1%)
- 2019 The Distinguished Graduates of Beijing (Top 1%)
- …
Academic Service
-
Conference Reviewer: CVPR, ICCV, ECCV, NeurIPS, ICLR, ICML, SIGGRAPH, SIGGRAPH Asia, AAAI.
-
Journal Reviewer: IEEE Transactions on Image Processing (Q1); IEEE Transactions on Geoscience and Remote Sensing (Q1); ISPRS Journal of Photogrammetry and Remote Sensing (Q1); IEEE Geoscience and Remote Sensing Letters (Q1); IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (Q1); Remote Sensing (Q1); International Journal of Digital Earth (Q1); IEEE Internet of Things Journal (Q1); Computer Science Review (Q1); Image and Vision Computing (Q1).
-
Teaching Assistant: EE4309 Robot Perception; EE6733 Advanced Topics on Vision and Machine Learning.
-- Tsiolkovsky

-- "Pale Blue Dot", taken by the Voyager 1